Initiez-vous au Deep Learning
Découvrez le Deep Learning, ses principes, applications et outils. Ce guide complet pour débutants vous aide à comprendre et démarrer avec cette technologie révolutionnaire.
Initiez-vous au Deep Learning
Le Deep Learning est l’une des branches les plus fascinantes de l’intelligence artificielle. Il permet aux machines d’apprendre à partir de données complexes, d’identifier des patterns et de prendre des décisions intelligentes. Dans ce guide complet, vous allez découvrir ses concepts fondamentaux, ses applications concrètes et comment commencer à l’utiliser.

Qu’est-ce que le Deep Learning ?
Le Deep Learning, ou apprentissage profond en français, est une sous-branche de l’intelligence artificielle (IA) qui permet aux machines d’apprendre et de prendre des décisions de manière autonome à partir de données.
Il s’agit d’une évolution du Machine Learning, mais avec une approche beaucoup plus puissante et sophistiquée.
Une inspiration venue du cerveau humain
Le Deep Learning s’inspire directement du fonctionnement du cerveau humain.
Tout comme notre cerveau est constitué de neurones interconnectés qui communiquent entre eux, le Deep Learning repose sur des réseaux de neurones artificiels (Artificial Neural Networks, ou ANN).
Ces réseaux sont organisés en couches successives de neurones :
une couche d’entrée, qui reçoit les données (par exemple, une image ou une phrase) ;
une ou plusieurs couches cachées (hidden layers), qui analysent et extraient progressivement les caractéristiques importantes de ces données ;
une couche de sortie, qui fournit le résultat final (par exemple, reconnaître un visage, traduire une phrase, ou prédire une valeur).
Chaque neurone est relié à d’autres par des poids — des valeurs numériques ajustées lors de l’entraînement du modèle — qui déterminent l’importance de chaque information transmise.
Une capacité d’apprentissage à partir de données massives
Ce qui distingue véritablement le Deep Learning du Machine Learning classique, c’est sa capacité à apprendre directement à partir de données brutes et non structurées.
Alors que le Machine Learning traditionnel nécessite souvent une phase de préparation manuelle des données (appelée feature engineering), le Deep Learning apprend automatiquement à reconnaître les caractéristiques pertinentes.
Prenons quelques exemples concrets :
Un réseau de neurones convolutif (CNN) peut apprendre à reconnaître un visage dans une photo sans qu’un humain ait besoin de définir manuellement ce qu’est un œil, un nez ou une bouche.
Un réseau de neurones récurrent (RNN) peut analyser une phrase mot par mot et en comprendre le sens global, sans qu’il soit nécessaire de lui expliquer la grammaire.
C’est cette capacité d’auto-apprentissage à partir d’énormes volumes de données qui rend le Deep Learning si performant dans les domaines comme :
la vision par ordinateur (reconnaissance d’images, détection d’objets, vidéosurveillance intelligente) ;
le traitement du langage naturel (NLP) (traduction automatique, génération de texte, assistants vocaux comme ChatGPT ou Alexa) ;
la reconnaissance vocale et audio (transcription automatique, analyse de son).
Comment le Deep Learning apprend-il ?
L’apprentissage profond repose sur un processus d’entraînement.
Voici les grandes étapes simplifiées :
Collecte de données : le modèle reçoit un grand ensemble d’exemples (par exemple, des milliers d’images de chats et de chiens).
Propagation avant (forward propagation) : les données passent dans le réseau, chaque couche extrait des informations de plus en plus abstraites.
Comparaison avec le résultat attendu : le modèle compare sa prédiction à la bonne réponse.
Rétropropagation (backpropagation) : une méthode mathématique ajuste les poids des neurones pour réduire l’erreur.
Répétition : ce processus se répète des milliers, voire des millions de fois, jusqu’à ce que le modèle atteigne une précision élevée.
Ainsi, plus un modèle de Deep Learning est entraîné sur des données variées et de qualité, plus il devient intelligent et précis.
En résumé
Le Deep Learning est bien plus qu’une simple technologie : c’est un moteur d’intelligence artificielle capable d’apprendre et de s’améliorer seul.
Il a permis des avancées spectaculaires dans la reconnaissance d’images, le traitement du langage, la santé, la finance ou encore les transports autonomes.
En bref :
Le Deep Learning permet aux machines d’apprendre directement à partir de données brutes, grâce à des réseaux de neurones inspirés du cerveau humain.
Plus on lui donne de données, plus il apprend, et plus il devient performant.
Les composants clés du Deep Learning
Découvrez le neurone formel
Dans ce chapitre, nous allons explorer les origines du neurone formel, comprendre son fonctionnement et apprendre comment l’entraîner.
Pour bien saisir cette notion, commençons par un détour fascinant : celui du neurone biologique, qui a inspiré toute la conception des réseaux de neurones artificiels.
Le neurone biologique : la source d’inspiration
Les réseaux de neurones artificiels (souvent abrégés en ANN pour Artificial Neural Networks) sont des modèles mathématiques directement inspirés du cerveau humain.
Leur brique de base, le neurone artificiel, est née du désir de modéliser le comportement d’un véritable neurone biologique.
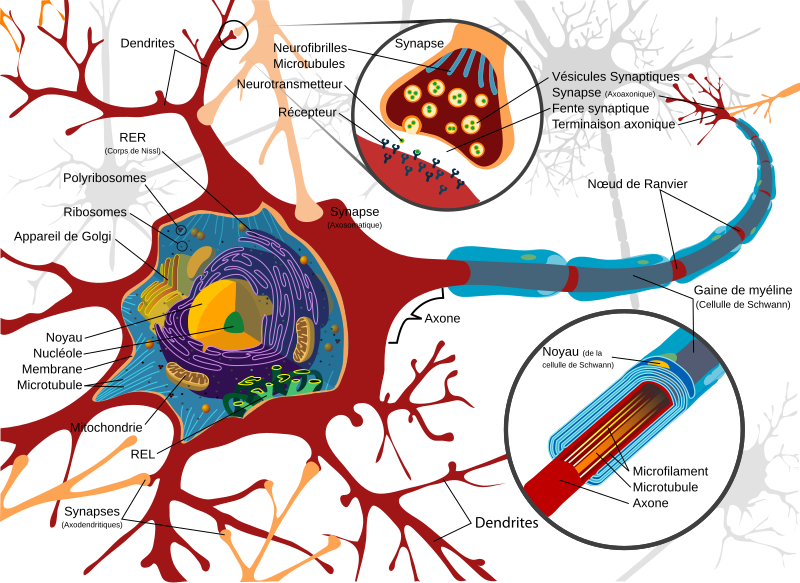
Un neurone biologique peut être schématiquement décomposé en trois grandes parties :
Le corps cellulaire (ou péricaryon) : centre de traitement du signal.
Les dendrites : prolongements multiples (souvent plus de 7 000) qui reçoivent les signaux provenant d’autres neurones.
L’axone : long prolongement unique qui transmet le signal à d’autres neurones.
Les dendrites jouent le rôle de capteurs. Elles reçoivent des signaux électriques, appelés influx nerveux, provenant d’autres neurones. Ces signaux convergent vers le corps cellulaire.
Lorsque le niveau d’excitation dépasse un certain seuil, un nouvel influx nerveux est généré et se propage le long de l’axone jusqu’à son extrémité.
C’est à cet endroit que se trouve la synapse, la zone de contact entre deux neurones, où l’information est transmise chimiquement ou électriquement à un autre neurone.
Ainsi, des réseaux entiers de neurones biologiques se forment pour permettre au cerveau d’analyser, apprendre et réagir.
Le neurone formel : la version mathématique du neurone biologique
Le neurone formel, aussi appelé perceptron ou neurone artificiel, est une abstraction mathématique du neurone biologique.
L’objectif est de reproduire le principe de traitement de l’information du cerveau humain, mais sous une forme simplifiée et calculable.
Bien sûr, le modèle ne cherche pas à imiter tous les processus biochimiques du cerveau.
Il s’agit plutôt d’une version symbolique, suffisante pour permettre à une machine d’apprendre à partir de données.
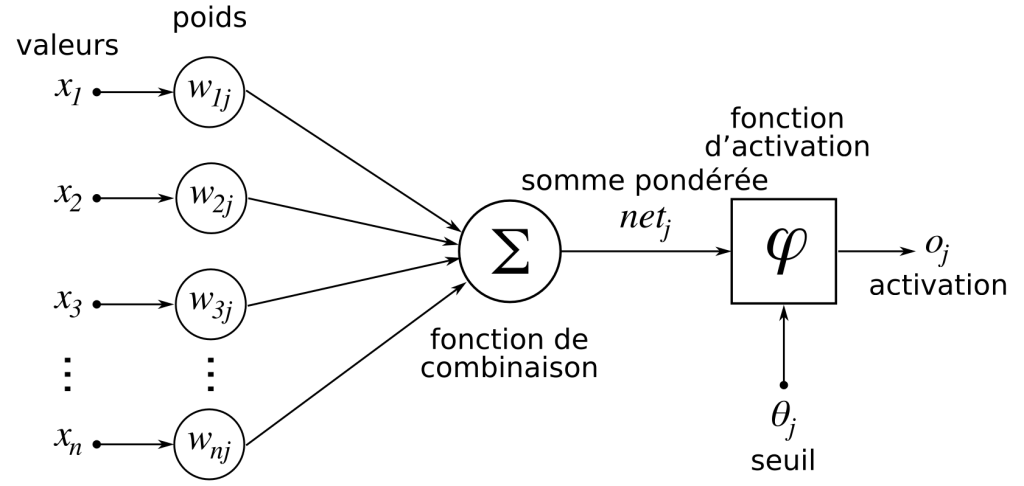
Structure d’un neurone formel
Un neurone formel peut être représenté ainsi :
Des entrées (notées x) : elles représentent les signaux reçus par le neurone, analogues aux dendrites.
Des poids (notés w) : coefficients qui indiquent l’importance de chaque entrée.
Un biais (noté b) : une valeur qui permet de décaler la décision du neurone.
Une fonction d’activation (notée f) : elle détermine la sortie finale en fonction de la somme pondérée des entrées.
Une sortie (notée ŷ) : le résultat calculé, équivalent au signal transmis par l’axone.
L’équation d’un neurone formel est donnée par :
y^=f(⟨w,x⟩+b)\hat{y} = f(\langle \mathbf{w}, \mathbf{x} \rangle + b)y^=f(⟨w,x⟩+b)
Autrement dit :
Chaque entrée xix_ixi est multipliée par un poids wiw_iwi.
Les résultats sont additionnés, puis on y ajoute un biais bbb.
Enfin, le tout passe par une fonction de transfert fff (souvent non linéaire, comme la sigmoïde, ReLU ou tanh) qui produit la sortie du neurone.
Contrairement au neurone biologique, où le signal est transmis par fréquence d’impulsions, le neurone formel fonctionne selon une modulation d’amplitude : la sortie dépend directement de la valeur numérique du signal combiné.
Exemple : une séparation linéaire simple
Prenons un exemple concret de classification binaire.
Nous avons plusieurs points que nous voulons classer en deux catégories distinctes.
Un neurone formel peut apprendre à les séparer à l’aide d’une droite de décision.
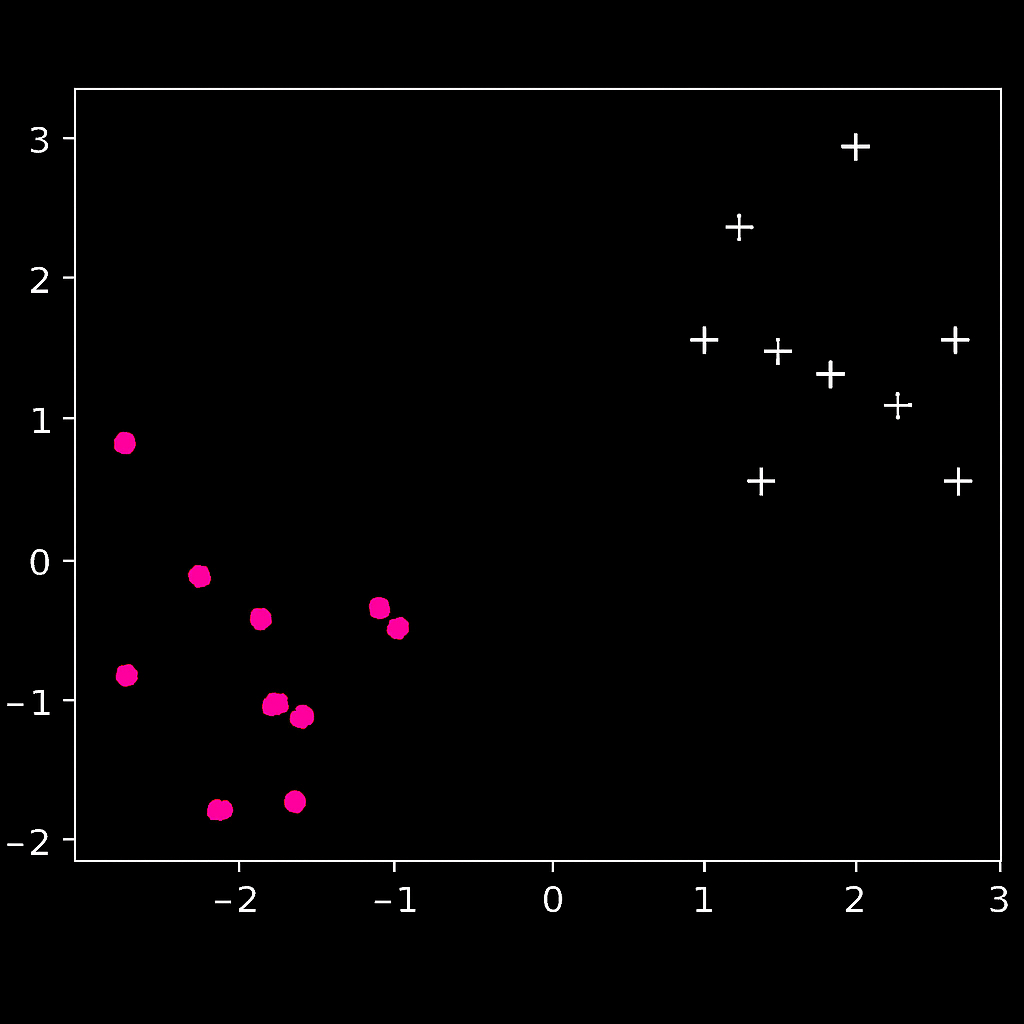
Si l’on choisit les paramètres suivants :
w=[0.9852 186],
b=−0.522
Le neurone calcule pour chaque point x la valeur y=f(⟨w,x⟩+b)
Les points pour lesquels le résultat est positif seront d’un côté de la droite, les négatifs de l’autre.
On obtient ainsi une séparation linéaire nette entre les deux classes.
C’est le principe de base du perceptron : apprendre à distinguer deux catégories à l’aide d’un seul neurone.
Apprentissage du neurone : la descente de gradient
Mais comment le neurone apprend-il à ajuster ses paramètres w\mathbf{w}w et bbb ?
C’est là qu’intervient la descente de gradient, une méthode d’optimisation fondamentale du Deep Learning.
L’idée est de minimiser une fonction de perte, c’est-à-dire une mesure de l’erreur entre les prédictions du neurone et les valeurs réelles.
Dans le cas d’une classification binaire, on utilise souvent la log-vraisemblance négative
Les paramètres sont ensuite mis à jour selon le gradient de cette fonction :
Visualisation de l’apprentissage
Si l’on visualise la fonction de décision au fil des itérations :
la zone magenta représente les sorties positives,
la zone cyan représente les sorties négatives.
Au fur et à mesure de la descente de gradient, la frontière de décision s’ajuste jusqu’à séparer parfaitement les deux catégories.
Pour aller plus loin
Article sur le Perceptron
Comprendre le perceptron : le neurone artificiel fondateur du Deep Learning (OpenClassrooms)
Cet article présente pas à pas le fonctionnement du perceptron, ses équations et ses limites, avec des exemples visuels concrets.
Les couches profondes (Deep Layers)
Les couches profondes constituent le cœur du Deep Learning. C’est d’ailleurs de là que vient le mot “deep” (profond).
Dans un réseau de neurones artificiels, les couches représentent les étapes successives de traitement par lesquelles passent les données.
Plus un réseau contient de couches, plus il peut apprendre des représentations abstraites et complexes du monde réel.
Structure d’un réseau profond
Un réseau de neurones est généralement organisé en trois grandes catégories de couches :
La couche d’entrée (Input Layer) — elle reçoit les données brutes, par exemple les pixels d’une image ou les mots d’une phrase.
Les couches cachées (Hidden Layers) — elles traitent progressivement les informations, en extrayant des motifs ou des caractéristiques de plus en plus sophistiquées.
La couche de sortie (Output Layer) — elle fournit le résultat final : une classification, une prédiction, une traduction, etc.
Chaque couche est composée de neurones formels qui transforment les signaux reçus à l’aide de poids, biais et fonctions d’activation.
Les sorties d’une couche deviennent les entrées de la couche suivante, créant ainsi une chaîne d’apprentissage hiérarchique.
Pourquoi “plus profond” veut dire “plus intelligent”
Dans un réseau peu profond (par exemple, un modèle avec une ou deux couches cachées), les informations traitées restent simples :
le modèle peut apprendre à distinguer des formes basiques, mais pas des structures complexes.
En revanche, un réseau profond (avec des dizaines, voire des centaines de couches) peut construire des représentations hiérarchiques :
Les premières couches détectent des éléments simples (bords, couleurs, sons).
Les couches intermédiaires combinent ces éléments pour reconnaître des motifs (yeux, mots, textures).
Les couches finales identifient des objets entiers ou des concepts (un visage, une phrase, une émotion).
C’est cette architecture en profondeur qui permet au Deep Learning de surpasser les méthodes classiques dans des domaines comme la vision, la reconnaissance vocale ou le traitement du langage.
Un équilibre entre profondeur et performance
Cependant, augmenter la profondeur d’un réseau ne suffit pas toujours à améliorer ses performances.
Des modèles trop profonds peuvent devenir difficiles à entraîner à cause de problèmes comme :
le gradient qui disparaît (vanishing gradient),
le surapprentissage (overfitting),
ou encore une consommation excessive de ressources.
Pour pallier ces limites, les chercheurs ont développé des architectures avancées telles que les réseaux convolutifs (CNN), les réseaux résiduels (ResNet) ou les Transformers, qui permettent de propager l’information efficacement tout en conservant la profondeur du modèle.
En résumé
Les couches profondes permettent à un réseau de neurones d’apprendre des représentations de plus en plus abstraites et complexes.
C’est cette hiérarchie d’informations qui donne au Deep Learning sa puissance et sa capacité à rivaliser — voire dépasser — les performances humaines dans certaines tâches cognitives.
Les fonctions d’activation : donner vie au réseau
Les fonctions d’activation sont un élément fondamental du Deep Learning.
Elles jouent un rôle décisif : transformer les signaux transmis d’un neurone à l’autre et permettre au réseau de modéliser des relations non linéaires entre les entrées et les sorties.
Sans elles, un réseau de neurones — aussi complexe soit-il — se comporterait simplement comme une fonction linéaire, incapable de résoudre des problèmes réels tels que la reconnaissance d’images, la traduction ou la prédiction de comportements.
Pourquoi les fonctions d’activation sont essentielles
Imaginons un réseau sans fonction d’activation :
chaque couche appliquerait uniquement une transformation linéaire (une somme pondérée des entrées).
Même en empilant des dizaines de couches, le résultat final resterait une combinaison linéaire des données d’entrée, limitant drastiquement les capacités du modèle.
Les fonctions d’activation introduisent donc la non-linéarité, c’est-à-dire la capacité du réseau à capturer des relations complexes et à apprendre des motifs cachés dans les données.
C’est grâce à elles qu’un réseau peut comprendre des concepts abstraits, reconnaître des visages, analyser des sentiments ou générer du texte.
Les principales fonctions d’activation utilisées
Voici les fonctions les plus courantes en Deep Learning, chacune ayant ses avantages selon le contexte :
1. Sigmoïde
Fonction sigmoïde :
$$ f(x) = \frac{1}{1 + e^{-x}} $$Elle transforme toute valeur d’entrée en un nombre compris entre 0 et 1.
Historiquement utilisée dans les premiers réseaux, elle est adaptée aux sorties probabilistes, mais peut poser des problèmes de saturation du gradient dans les couches profondes.
2. Tanh (Tangente hyperbolique)
Proche de la sigmoïde, mais avec des valeurs comprises entre –1 et +1, elle offre une meilleure symétrie et accélère parfois la convergence de l’apprentissage.
3. ReLU (Rectified Linear Unit)
La ReLU est aujourd’hui la fonction d’activation la plus utilisée.
Simple, rapide à calculer et efficace, elle permet d’éviter le problème du gradient qui disparaît.
Cependant, elle peut “bloquer” certains neurones (on parle de neurones morts) si les entrées deviennent trop négatives.
4. Leaky ReLU et variantes
Ces variantes corrigent le problème des neurones inactifs en autorisant un petit flux d’information même pour les valeurs négatives.
5. Softmax
Utilisée dans la couche de sortie des réseaux de classification multiclasse, la Softmax convertit les valeurs en probabilités qui s’additionnent à 1.
Choisir la bonne fonction d’activation
Le choix d’une fonction d’activation dépend du type de tâche et de l’architecture du réseau :
| Cas d’usage | Fonction d’activation recommandée |
|---|---|
| Couches cachées d’un réseau profond | ReLU ou Leaky ReLU |
| Réseaux récurrents (NLP, séries temporelles) | Tanh ou ReLU |
| Sortie pour classification binaire | Sigmoïde |
| Sortie pour classification multiclasse | Softmax |
Bien choisie, une fonction d’activation permet au réseau d’apprendre plus vite, plus profondément et de généraliser sur de nouvelles données.
En résumé
Les fonctions d’activation apportent la non-linéarité indispensable au Deep Learning.
Sans elles, les réseaux de neurones ne pourraient pas apprendre de relations complexes ni modéliser le monde réel.
ReLU, Sigmoïde, Tanh ou Softmax : chacune joue un rôle spécifique selon la nature du problème à résoudre.
Les algorithmes d’optimisation : le moteur de l’apprentissage
Les algorithmes d’optimisation sont le cœur battant du Deep Learning.
Ce sont eux qui permettent à un réseau de neurones d’apprendre à partir de ses erreurs, en ajustant progressivement les poids (ou paramètres) de chaque neurone pour réduire l’erreur du modèle.
Sans ces algorithmes, un réseau resterait figé, incapable de s’améliorer.
Grâce à eux, il devient capable de reconnaître un visage, traduire une phrase ou prédire un mouvement boursier — tout cela en s’ajustant itérativement, millions de fois, pour minimiser sa fonction de perte (loss function).
Comment fonctionne une optimisation dans un réseau de neurones ?
L’objectif est simple : trouver l’ensemble des poids optimaux qui minimisent l’erreur entre la prédiction du modèle et la valeur réelle.
Le processus se déroule en trois étapes principales :
Propagation avant (Forward pass) :
Les données passent à travers le réseau, produisant une prédiction.Calcul de l’erreur (Loss) :
La différence entre la prédiction et la vérité est mesurée via une fonction de perte (comme l’erreur quadratique moyenne ou l’entropie croisée).Rétropropagation (Backpropagation) :
L’algorithme d’optimisation met à jour les poids en fonction du gradient de la perte — c’est-à-dire la direction dans laquelle le modèle doit “bouger” pour s’améliorer.
C’est ici qu’interviennent des méthodes comme SGD ou Adam.
Les principaux algorithmes d’optimisation en Deep Learning
1. SGD (Stochastic Gradient Descent)
Le descente de gradient stochastique est la méthode la plus classique et la plus fondamentale.
Elle met à jour les poids selon la règle :
où :
www = poids du neurone,
η\etaη = taux d’apprentissage (learning rate),
∂L∂w\frac{\partial L}{\partial w}∂w∂L = dérivée de la fonction de perte par rapport au poids.
Avantages : simple, rapide, efficace sur de grands volumes de données.
Inconvénients : peut osciller ou se bloquer dans des minima locaux si le taux d’apprentissage n’est pas bien réglé.
2. Momentum
Pour améliorer la stabilité de la descente, Momentum ajoute un effet “d’inertie” : les mises à jour prennent en compte la direction précédente du gradient.
Cela permet de converger plus rapidement et d’éviter les oscillations.
C’est un peu comme une balle qui roule dans une vallée : elle accumule de la vitesse dans la bonne direction.
3. Adam (Adaptive Moment Estimation)
L’algorithme Adam est aujourd’hui le plus utilisé en Deep Learning.
Il combine les avantages de Momentum et d’AdaGrad, en adaptant le taux d’apprentissage pour chaque paramètre.
Formule simplifiée :
où :
m^\hat{m}m^ et v^\hat{v}v^ représentent les moyennes mobiles du gradient et de son carré.
Avantages :
Convergence rapide,
Excellente stabilité,
Moins sensible au choix du taux d’apprentissage.
Inconvénients : parfois, une convergence trop rapide peut conduire à des solutions sous-optimales.
4. RMSProp
Conçu pour les réseaux récurrents (RNN), RMSProp ajuste le taux d’apprentissage de manière adaptative en fonction de la moyenne des carrés du gradient.
Cela aide à stabiliser l’entraînement sur des données séquentielles (comme le texte ou l’audio).
Comparatif rapide
| Algorithme | Vitesse | Stabilité | Adaptatif | Idéal pour |
|---|---|---|---|---|
| SGD | Moyenne | Moyenne | ❌ Non | Projets simples, bases théoriques |
| Momentum | Rapide | Bonne | ❌ Non | Convergence stable |
| RMSProp | Rapide | Très bonne | ✅ Oui | Données séquentielles |
| Adam | Très rapide | Excellente | ✅ Oui | Réseaux profonds et grands jeux de données |
En résumé
Les algorithmes d’optimisation sont les artisans invisibles de l’apprentissage profond.
Grâce à eux, les réseaux ajustent des millions de paramètres pour améliorer leurs performances.
Du SGD au Adam, chaque méthode cherche le juste équilibre entre vitesse, précision et stabilité.
Applications concrètes du Deep Learning
Le Deep Learning n’est pas une simple avancée technologique : c’est une révolution silencieuse qui redessine les frontières de la science, de l’industrie et même de notre quotidien.
Derrière chaque innovation majeure — des véhicules autonomes aux assistants vocaux — se cachent des réseaux de neurones profonds capables d’apprendre, de percevoir et de décider.
Parmi les domaines les plus bouleversés, la vision par ordinateur se distingue comme l’un des joyaux du Deep Learning.
Vision par ordinateur : quand les machines apprennent à voir
Longtemps, la vision a été un privilège du vivant.
Aujourd’hui, grâce au Deep Learning, les machines voient, interprètent et reconnaissent le monde qui les entoure avec une précision parfois supérieure à celle de l’œil humain.
Au cœur de cette prouesse, on trouve les réseaux de neurones convolutifs (CNN – Convolutional Neural Networks), conçus pour analyser des images de manière hiérarchique — des pixels bruts jusqu’à la reconnaissance d’objets complexes.
1. Reconnaissance d’images : l’œil numérique
La reconnaissance d’images est l’une des premières victoires spectaculaires du Deep Learning.
Des modèles comme AlexNet, ResNet ou EfficientNet ont propulsé la précision des systèmes de classification à des niveaux inégalés.
Concrètement, le réseau apprend à identifier les caractéristiques visuelles clés : formes, textures, couleurs, contrastes.
En combinant ces éléments, il parvient à reconnaître un chat, une fleur, ou même une tumeur sur une radiographie médicale.
Exemples d’applications :
Systèmes de tri automatisés dans l’industrie agroalimentaire.
Applications mobiles de reconnaissance d’objets.
Diagnostic médical assisté par IA pour la détection de maladies oculaires, pulmonaires ou dermatologiques.
Chaque image devient une donnée porteuse de sens, et le réseau, un interprète visuel d’une acuité exceptionnelle.
2. Détection d’objets : comprendre la scène
Voir ne suffit pas : il faut comprendre.
C’est ici qu’interviennent les modèles de détection d’objets tels que YOLO (You Only Look Once) ou Faster R-CNN.
Ils permettent à une IA non seulement de reconnaître un objet, mais aussi de le localiser avec précision dans une image ou une vidéo.
Par exemple, une voiture autonome ne se contente pas d’identifier un piéton : elle anticipe sa trajectoire, distingue un feu rouge d’un feu vert et comprend la scène routière dans son ensemble.
Applications clés :
Surveillance intelligente et sécurité urbaine.
Comptage automatique d’objets dans les entrepôts ou magasins.
Assistance à la conduite et systèmes de freinage d’urgence.
La détection d’objets, c’est l’intelligence du regard : une machine capable non seulement de voir, mais de contextualiser ce qu’elle voit.
Véhicules autonomes : la route vers l’intelligence mobile
Le véhicule autonome est sans doute l’une des incarnations les plus fascinantes du Deep Learning.
Ses “yeux”, ce sont des caméras haute définition couplées à des capteurs (LIDAR, radar, GPS).
Son “cerveau”, ce sont des réseaux de neurones profonds capables d’interpréter des millions d’images par seconde pour percevoir, décider et agir.
Chaque seconde, le système analyse l’environnement :
il reconnaît les obstacles,
anticipe les comportements des autres usagers,
et choisit la trajectoire la plus sûre.
Des modèles comme Tesla Autopilot ou Waymo Driver reposent sur des architectures massives de Deep Learning, alimentées par d’immenses volumes de données issues de la route réelle.
Grâce à ces avancées, la promesse d’une mobilité intelligente et sécurisée devient chaque jour plus tangible.
En résumé
Le Deep Learning a offert aux machines un nouveau sens : la vision.
De la reconnaissance d’images à la conduite autonome, il transforme des pixels en décisions, des données en compréhension.
Ce que l’œil perçoit, le réseau de neurones le décode, l’analyse et l’interprète avec une logique d’une précision inédite.
Traitement du langage naturel (NLP) : quand les machines apprennent à comprendre les mots
Si la vision artificielle permet aux machines de voir, le traitement du langage naturel — ou NLP (Natural Language Processing) — leur permet de comprendre, parler et écrire.
C’est l’un des champs les plus fascinants du Deep Learning, car il touche à ce qui fait l’essence même de l’intelligence humaine : le langage.
Grâce à des modèles neuronaux profonds, les machines ne se contentent plus de lire des mots ; elles en saisissent le sens, les nuances et même les émotions.
Le pouvoir des réseaux de neurones linguistiques
Le Deep Learning a bouleversé le NLP en donnant naissance à une nouvelle génération de modèles capables de traiter le texte comme une séquence vivante.
Des architectures telles que les RNN (Recurrent Neural Networks), les LSTM (Long Short-Term Memory) et surtout les Transformers (comme BERT, GPT, T5 ou LLaMA) ont permis aux IA de comprendre la structure et le contexte d’un langage avec une finesse jamais atteinte.
Ces modèles n’apprennent pas simplement des règles grammaticales : ils absorbent des milliards de phrases, en extraient les relations sémantiques, et deviennent capables de raisonner sur le texte.
Traduction automatique : briser les barrières linguistiques
La traduction automatique est l’une des applications historiques et les plus impressionnantes du NLP.
Grâce à des modèles comme Google Translate, DeepL ou M2M-100 (Meta), il est désormais possible de traduire instantanément des textes entre plus de 100 langues, avec un niveau de fluidité presque humain.
Comment ça fonctionne ?
Les réseaux de neurones encodeurs-décodeurs (Encoder-Decoder) transforment une phrase source en une représentation numérique du sens, puis la reconstituent dans la langue cible.
Ce processus ne traduit pas mot à mot, mais idée par idée — comme le ferait un traducteur humain expérimenté.
Impact concret :
Outils de communication multilingue dans les entreprises.
Accessibilité du savoir scientifique et culturel.
Facilitation du commerce international et du e-learning.
Le Deep Learning a fait de la diversité linguistique un pont, non plus une barrière.
Chatbots intelligents : la conversation devient naturelle
Les chatbots modernes ne se contentent plus de réponses préprogrammées.
Grâce au Deep Learning et aux architectures de type Transformer, ils peuvent comprendre le contexte, adapter leur ton et générer des réponses cohérentes et pertinentes.
Des assistants conversationnels comme ChatGPT, Claude, Gemini ou Mistral incarnent cette nouvelle génération de modèles.
Ils apprennent à partir d’énormes corpus de textes, leur permettant de converser, d’enseigner, d’aider à la rédaction ou même de résoudre des problèmes complexes.
Applications réelles :
Service client automatisé 24/7.
Accompagnement pédagogique personnalisé.
Création de contenu intelligent et assisté par IA.
Ces outils ne remplacent pas l’humain : ils amplifient sa productivité et libèrent du temps pour la créativité.
Assistants vocaux : la voix, nouveau langage de l’IA
Siri, Alexa, Google Assistant… Ces noms nous sont familiers, mais derrière leur apparente simplicité se cache une architecture neuronale d’une puissance vertigineuse.
Leur force repose sur deux piliers du Deep Learning :
la reconnaissance vocale (Speech-to-Text),
et la compréhension du langage naturel (NLU – Natural Language Understanding).
Ainsi, quand vous demandez « Quelle est la météo à Cotonou ? », le système :
Convertit le son en texte,
Analyse le sens de la phrase,
Cherche la réponse dans sa base de données,
Puis vous la restitue par synthèse vocale (Text-to-Speech).
Ces technologies transforment notre rapport aux machines :
elles rendent les interactions plus humaines, naturelles et fluides.
En résumé
Le NLP est le souffle qui donne aux machines la parole et la compréhension.
De la traduction automatique aux assistants vocaux, il relie les mondes linguistiques, simplifie nos échanges et réinvente la communication entre l’humain et la machine.
Grâce au Deep Learning, la langue n’est plus une frontière : elle devient un pont universel entre les esprits.

Santé et médecine : le Deep Learning au service du diagnostic médical
Parmi toutes les révolutions portées par le Deep Learning, celle de la médecine est sans doute la plus humaine et la plus porteuse d’espoir.
Les réseaux de neurones profonds ne se contentent plus d’analyser des chiffres ou des images : ils sauvent des vies.
En combinant puissance de calcul, précision mathématique et apprentissage à partir de millions d’examens, le Deep Learning devient un allié incontournable du corps médical — notamment dans le diagnostic à partir d’images radiologiques.
Quand les réseaux de neurones deviennent des radiologues virtuels
Les réseaux de neurones convolutifs (CNN), déjà maîtres dans la reconnaissance d’images, se sont révélés être des outils remarquables pour l’analyse d’imagerie médicale : radiographies, IRM, scanners, mammographies, échographies…
Leur principe est simple, mais redoutablement efficace :
ils apprennent à détecter des motifs invisibles à l’œil humain, des anomalies subtiles, et à les associer à des pathologies spécifiques.
Grâce à cet apprentissage supervisé, ces modèles peuvent reconnaître une lésion, une fracture, une tumeur, ou encore les signes précoces d’une maladie neurodégénérative.
Un diagnostic assisté, mais pas remplacé
Contrairement à une idée reçue, le Deep Learning ne remplace pas le médecin : il l’assiste.
Il agit comme un second regard numérique, capable d’analyser rapidement des milliers d’images et de signaler des zones suspectes.
Par exemple :
En radiologie thoracique, il aide à détecter des nodules pulmonaires indicateurs d’un cancer.
En ophtalmologie, il identifie les signes précoces de rétinopathie diabétique sur des photographies de la rétine.
En oncologie, il segmente automatiquement les tumeurs cérébrales sur les IRM, facilitant la planification des traitements.
Résultat : un diagnostic plus rapide, plus précis et surtout plus accessible, même dans les régions où les spécialistes manquent.
Le fonctionnement d’un modèle d’analyse médicale
Un modèle de Deep Learning médical suit un processus rigoureux et encadré :
Collecte des données : des milliers d’images médicales annotées par des experts.
Prétraitement : normalisation, suppression du bruit, équilibrage des classes.
Entraînement du réseau : le modèle apprend à distinguer les tissus sains des tissus pathologiques.
Évaluation clinique : validation sur des jeux de données indépendants, souvent multicentriques.
Déploiement hospitalier : intégration dans les systèmes PACS (Picture Archiving and Communication System) ou les plateformes de télémédecine.
Ces étapes garantissent que les algorithmes respectent les normes médicales et éthiques avant toute mise en service.
Des exemples concrets dans le monde médical
Google DeepMind a développé un modèle capable de diagnostiquer plus de 50 maladies oculaires avec une précision équivalente à celle d’un ophtalmologue.
IBM Watson Health utilise l’IA pour analyser des milliers de dossiers médicaux et proposer des recommandations thérapeutiques personnalisées.
Des startups comme Aidoc, Zebra Medical Vision ou PathAI créent des outils capables de repérer des anomalies en quelques secondes, là où un humain mettrait plusieurs minutes.
Ces innovations montrent que le Deep Learning ne se contente pas de traiter des données : il accélère la recherche médicale, améliore la détection précoce, et sauve des vies chaque jour.
Les enjeux éthiques et humains
L’IA médicale pose aussi des questions fondamentales :
Qui est responsable en cas d’erreur ? Comment garantir la confidentialité des données de santé ?
Comment éviter les biais dans les jeux d’entraînement, qui pourraient entraîner des diagnostics inégaux selon les populations ?
C’est pourquoi les chercheurs et médecins insistent sur une approche dite de l’IA éthique — où la technologie reste un outil au service du jugement humain.
L’objectif n’est pas de remplacer le praticien, mais de renforcer ses capacités diagnostiques et réduire les inégalités d’accès aux soins.
En résumé
Le Deep Learning médical incarne la promesse d’une médecine plus rapide, plus précise et plus humaine.
En associant la rigueur du calcul à la bienveillance du soin, il ouvre la voie à une ère nouvelle : celle où la donnée devient guérison, et l’algorithme, un allié du médecin.

Finance : le Deep Learning au cœur de l’analyse prédictive et de la cybersécurité financière
Dans les coulisses des marchés financiers, des millions de données circulent chaque seconde : cours boursiers, indicateurs économiques, transactions, volumes d’échange, comportements d’investisseurs…
Dans cet océan d’informations, le Deep Learning agit comme un radar intelligent, capable de détecter les signaux cachés, anticiper les tendances et prévenir les risques.
De la prévision des marchés à la détection de fraude, cette technologie transforme la finance en une science des décisions assistées par l’intelligence artificielle.
Analyse prédictive et trading intelligent
L’un des champs d’application les plus puissants du Deep Learning en finance est sans doute l’analyse prédictive.
Les modèles de réseaux neuronaux, notamment les RNN (Recurrent Neural Networks), LSTM (Long Short-Term Memory) et Transformers, sont capables d’apprendre les mouvements temporels complexes des marchés.
Ces modèles traitent des séries temporelles financières (prix, volumes, volatilité) pour anticiper les fluctuations futures.
En intégrant des données externes — comme les actualités économiques, les tweets ou les événements géopolitiques —, ils peuvent même détecter des corrélations invisibles à l’œil humain.
Applications concrètes :
Prédiction des cours boursiers à court ou moyen terme.
Détection de signaux de retournement du marché.
Optimisation de portefeuilles basée sur le risque et la volatilité.
Automatisation du trading (trading algorithmique) avec adaptation en temps réel.
Le Deep Learning donne ainsi naissance à une nouvelle génération de traders artificiels, capables d’apprendre de leurs erreurs, d’adapter leurs stratégies et d’agir en quelques millisecondes.
Détection de fraude et sécurité financière
L’autre grande révolution du Deep Learning en finance se situe du côté de la sécurité et de la conformité.
Les banques et plateformes de paiement doivent surveiller des milliards de transactions chaque jour — une tâche impossible à réaliser manuellement.
Les réseaux neuronaux profonds permettent de détecter automatiquement des comportements suspects, en apprenant les schémas normaux d’activité pour ensuite repérer les anomalies.
Exemples d’usages :
Détection en temps réel de transactions frauduleuses sur carte bancaire.
Identification de tentatives de blanchiment d’argent (AML) grâce à l’analyse de graphes de relations.
Surveillance des opérations internes pour prévenir les abus de marché.
Les modèles de Deep Learning, en combinant analyse comportementale, données historiques et signatures numériques, permettent d’atteindre des taux de détection supérieurs à 95 % tout en réduisant les faux positifs.
Ainsi, la technologie devient un gardien invisible, protégeant les flux financiers avec une vigilance constante.
Les atouts du Deep Learning dans la finance moderne
| Domaine | Application | Bénéfice clé |
|---|---|---|
| Trading algorithmique | Prédiction et exécution automatique | Rapidité et optimisation des stratégies |
| Gestion des risques | Simulation de scénarios économiques | Meilleure anticipation des crises |
| Détection de fraude | Identification d’anomalies transactionnelles | Sécurité accrue et conformité réglementaire |
| Analyse de sentiment | Étude des émotions du marché via les réseaux sociaux | Indicateurs comportementaux puissants |
| Crédit scoring | Évaluation des profils emprunteurs | Décisions plus justes et plus inclusives |
Le Deep Learning ne se limite donc pas à la prédiction : il structure, sécurise et humanise la finance en redonnant du sens à la donnée.
Exemples d’acteurs et d’innovations
JP Morgan Chase utilise des réseaux neuronaux pour surveiller les risques de marché et automatiser certaines décisions d’investissement.
Mastercard et PayPal exploitent des modèles d’IA pour repérer les transactions anormales en quelques millisecondes.
Des hedge funds quantitatifs comme Renaissance Technologies ou Two Sigma s’appuient sur des architectures de Deep Learning pour détecter des opportunités invisibles dans les flux boursiers mondiaux.
Chaque innovation trace la voie vers une finance prédictive, adaptative et résiliente.
En résumé
Le Deep Learning transforme la finance en une intelligence des marchés.
Il lit les tendances, anticipe les risques et protège les flux financiers avec une précision inégalée.
Entre trading prédictif et cybersécurité bancaire, il fait entrer le monde financier dans une ère où les algorithmes apprennent à lire l’avenir.

Industrie : le Deep Learning au service de l’efficacité et de la prévision
Dans le monde industriel, le Deep Learning est en train de réinventer la production, réduire les coûts et prévenir les pannes avant qu’elles ne surviennent.
Grâce à la puissance des réseaux neuronaux profonds, les machines ne se contentent plus d’exécuter des tâches : elles apprennent, anticipent et optimisent les processus de manière autonome.
Maintenance prédictive : anticiper plutôt que réparer
La maintenance prédictive est sans doute l’une des applications les plus concrètes et lucratives du Deep Learning en industrie.
Au lieu d’attendre qu’une machine tombe en panne, les algorithmes analysent des millions de données en temps réel : vibrations, températures, pressions, courants électriques, et historiques de fonctionnement.
Comment ça fonctionne ?
Les capteurs installés sur les machines collectent continuellement des mesures.
Les réseaux de neurones apprennent les schémas normaux de fonctionnement.
Tout écart ou anomalie est détecté automatiquement, et le modèle peut prédire la probabilité de panne dans les heures, jours ou semaines à venir.
Bénéfices concrets :
Réduction des arrêts non planifiés.
Diminution des coûts de maintenance.
Allongement de la durée de vie des équipements.
Optimisation des stocks de pièces détachées.
Des entreprises comme Siemens, GE Aviation ou Bosch utilisent déjà ces technologies pour transformer leurs lignes de production en systèmes intelligents et proactifs.
Automatisation des processus : des usines intelligentes
Au-delà de la maintenance, le Deep Learning joue un rôle clé dans l’automatisation avancée des processus industriels.
Les réseaux neuronaux permettent de contrôler, superviser et optimiser des chaînes de production complexes : robots collaboratifs, tri automatique, assemblage de précision, inspection qualité…
Exemples d’applications :
Inspection visuelle automatisée : détection de défauts invisibles à l’œil humain sur des pièces ou des produits finis.
Robots intelligents : adaptation en temps réel aux variations de matériaux ou aux conditions de travail.
Optimisation énergétique : régulation automatique des systèmes pour réduire la consommation d’électricité ou de carburant.
Ces innovations transforment les usines traditionnelles en véritables écosystèmes intelligents, capables d’apprendre et de s’auto-ajuster pour produire plus vite, mieux et de manière plus durable.
Les technologies sous-jacentes
| Technologie | Rôle en industrie | Exemple d’usage |
|---|---|---|
| CNN (Convolutional Neural Networks) | Analyse d’images pour inspection visuelle | Détection de défauts sur des circuits imprimés |
| RNN / LSTM | Analyse de séries temporelles | Prévision de pannes ou fluctuations de production |
| Reinforcement Learning | Optimisation des chaînes de production | Contrôle automatique de robots et systèmes automatisés |
| Autoencoders | Détection d’anomalies | Identification de comportements anormaux dans les équipements |
Grâce à cette combinaison de techniques, le Deep Learning devient l’outil de prédiction et de décision ultime dans le secteur industriel.
En résumé
Le Deep Learning transforme l’industrie en un écosystème intelligent et anticipatif.
De la maintenance prédictive à l’automatisation des processus, il permet d’optimiser les performances, de réduire les coûts et de prévenir les pannes.
L’usine du futur n’est plus seulement mécanique : elle est connectée, intelligente et capable d’apprendre de ses propres données.

Différence entre Machine Learning et Deep Learning
Bien que le Deep Learning soit une branche du Machine Learning, il se distingue par sa capacité à traiter des problèmes beaucoup plus complexes et des volumes de données massifs. Comprendre ces différences est essentiel pour choisir la bonne approche selon vos besoins et vos données.
| Critère | Machine Learning | Deep Learning |
|---|---|---|
| Données | Petites ou moyennes quantités | Très grandes quantités, souvent massives et hétérogènes |
| Prétraitement | Nécessaire : les données doivent être nettoyées et transformées manuellement | Moins nécessaire : les modèles peuvent apprendre directement à partir de données brutes |
| Complexité | Faible à moyenne, architectures simples | Très élevée, avec de multiples couches et millions de paramètres |
| Exemples d’algorithmes | Régression linéaire, SVM, Random Forest | CNN, RNN, Transformers |
Données : le carburant de l’apprentissage
Le Machine Learning traditionnel fonctionne bien avec des ensembles de données limités et structurés. Il nécessite souvent un prétraitement minutieux pour que les modèles puissent apprendre efficacement.
Le Deep Learning, en revanche, brille avec d’énormes volumes de données, souvent non structurées comme des images, du texte ou de l’audio. Plus les données sont riches, plus le réseau profond peut extraire des motifs complexes et des relations cachées.
Prétraitement : manuel vs automatique
Dans le Machine Learning classique, vous devez souvent transformer vos données : normalisation, encodage, extraction de caractéristiques.
Avec le Deep Learning, la plupart des architectures modernes, comme les CNN ou Transformers, apprennent automatiquement les représentations utiles directement à partir des données brutes.
Résultat : moins de travail manuel et plus de capacité à découvrir des relations complexes que l’humain ne pourrait pas identifier.
Complexité des modèles
Le Machine Learning utilise généralement des modèles simples à moyens, adaptés à des problèmes linéaires ou légèrement non linéaires.
Le Deep Learning, en revanche, repose sur des architectures profondes, avec des dizaines voire des centaines de couches et des millions de paramètres. Cette complexité permet de modéliser des relations extrêmement subtiles et de résoudre des tâches que le Machine Learning classique ne pourrait pas gérer.
Exemples d’applications
Machine Learning classique :
Prédiction de prix via régression linéaire
Classification avec SVM ou Random Forest
Détection d’anomalies simples
Deep Learning :
Reconnaissance d’images avec CNN
Traitement de séquences et prédiction temporelle avec RNN
Analyse et génération de texte avec Transformers
En résumé, le Deep Learning est particulièrement puissant pour les problèmes nécessitant de grandes quantités de données et des modèles complexes, tandis que le Machine Learning classique reste efficace pour des tâches plus simples et des jeux de données limités.
Les réseaux de neurones les plus utilisés
CNN (Convolutional Neural Networks)
Idéal pour la vision par ordinateur, les CNN peuvent analyser des images en détectant automatiquement des motifs hiérarchiques : pixels → textures → objets.
Applications : reconnaissance d’images, détection d’objets, imagerie médicale.
RNN (Recurrent Neural Networks)
Adapté aux données séquentielles, les RNN conservent une mémoire de l’historique des données.
Applications : traduction automatique, génération de texte, reconnaissance vocale, prévision de séries temporelles.
Transformers
Révolutionnant le NLP moderne, les Transformers utilisent un mécanisme d’attention pour analyser le contexte global d’une séquence, même très longue.
Applications : chatbots avancés, modèles de langage (GPT, BERT), résumé automatique de documents.
En résumé
Le Machine Learning est idéal pour des tâches simples avec peu de données, tandis que le Deep Learning excelle dans des contextes complexes, avec de grandes quantités de données et des modèles profonds.
Les architectures clés — CNN, RNN et Transformers — permettent de traiter respectivement les images, les séquences et le langage, rendant le Deep Learning incontournable dans de nombreux domaines modernes.

Comment débuter en Deep Learning ?
Entrer dans l’univers du Deep Learning peut sembler intimidant au premier abord, mais avec la bonne approche, tout le monde peut s’y former efficacement.
Le secret : commencer simple, pratiquer souvent et apprendre en construisant.
Voici les étapes essentielles pour te lancer dans ce domaine fascinant.
Choisir un langage de programmation adapté
Le langage Python est la référence absolue en Deep Learning.
Sa syntaxe simple et sa communauté immense en font l’outil de choix pour les chercheurs, étudiants et ingénieurs.
Il dispose de puissantes bibliothèques dédiées à l’IA :
TensorFlow (Google) : pour construire, entraîner et déployer des modèles complexes.
Keras : une interface intuitive pour concevoir rapidement des réseaux de neurones.
PyTorch (Meta) : apprécié pour sa flexibilité et son approche plus « code-first ».
Astuce : installe Anaconda ou Google Colab pour expérimenter facilement sans configuration compliquée.
Acquérir les bases mathématiques indispensables
Le Deep Learning repose sur des concepts mathématiques fondamentaux.
Pas besoin d’être un génie en mathématiques, mais comprendre les bases t’aidera à interpréter et améliorer tes modèles.
Voici les notions clés à maîtriser :
Algèbre linéaire : vecteurs, matrices, multiplications matricielles (utilisées dans les réseaux neuronaux).
Statistiques et probabilités : distributions, espérances, variance, échantillonnage.
Calcul différentiel : dérivées et gradients, indispensables pour la descente de gradient et l’optimisation.
Objectif : savoir pourquoi un modèle apprend, pas seulement comment il apprend.
Suivre des tutoriels et pratiquer pas à pas
Le meilleur moyen d’apprendre, c’est de coder.
Commence par des projets simples pour bien comprendre le fonctionnement d’un réseau de neurones :
Reconnaissance d’images : classer des chiffres manuscrits avec le dataset MNIST.
Chatbot simple : construire un petit modèle NLP avec des réponses automatiques.
Analyse de sentiment : classer des commentaires en positifs ou négatifs.
Ressources utiles :
Ces plateformes offrent des notebooks interactifs, des jeux de données et des projets à reproduire pas à pas.
Travailler sur des projets réels
Une fois les bases acquises, passe à la pratique sur des projets concrets.
La plateforme Kaggle est une véritable mine d’or pour les débutants comme les experts.
Tu y trouveras :
Des datasets publics (images, textes, signaux, données tabulaires).
Des compétitions où tu peux confronter tes modèles à ceux d’autres data scientists.
Une communauté active qui partage du code, des astuces et des notebooks pédagogiques.
Participer à ces projets t’apprend à résoudre des problèmes réels, à collaborer et à optimiser tes modèles pour obtenir de meilleures performances.
En résumé
Commencer en Deep Learning, c’est combiner curiosité, rigueur et expérimentation.
En maîtrisant Python, les mathématiques de base et les outils pratiques, tu peux rapidement créer tes premiers modèles et rejoindre la communauté mondiale de l’IA.
Le Deep Learning n’est plus réservé aux chercheurs :
il est aujourd’hui accessible à tous, à condition de se lancer avec méthode et passion.

Conclusion
Le Deep Learning s’impose aujourd’hui comme l’un des piliers de l’intelligence artificielle moderne.
Il ne s’agit plus d’une discipline réservée aux chercheurs ou aux grandes entreprises technologiques : chaque passionné de science, de données ou de technologie peut désormais s’y initier et créer des solutions innovantes.
Comprendre ses concepts fondamentaux — réseaux de neurones, fonctions d’activation, algorithmes d’optimisation — permet d’appréhender les mécanismes qui animent les systèmes intelligents d’aujourd’hui :
des voitures autonomes aux assistants vocaux, en passant par la médecine prédictive et le trading algorithmique.
Mais la maîtrise du Deep Learning ne repose pas uniquement sur la théorie.
C’est en expérimentant — en construisant, testant et améliorant des modèles — que l’on progresse véritablement.
Chaque projet, même modeste, t’apporte une compréhension concrète et développe ton intuition de data scientist.
Astuce pratique : commence petit.
Lance-toi dans un projet simple, comme un classificateur d’images ou un prédicteur de texte, pour t’immerger dans la logique des réseaux neuronaux.
Ces premières expériences t’aideront à acquérir les bons réflexes et à renforcer ta confiance.
Enfin, si ton objectif est de rendre ton travail visible, n’oublie pas que le Deep Learning et le SEO partagent une philosophie commune :
l’apprentissage continu et l’optimisation par l’expérience.
En appliquant de bonnes pratiques de référencement à ton contenu sur l’IA, tu feras briller ton expertise autant auprès des moteurs de recherche que des lecteurs curieux.



{kind=link}